Developer update: 275% improved game compression
Our database runs on 3 servers (1 primary, 2 secondaries), each with two 480GB SSDs in a RAID 1 configuration, and one server with a 1h delayed replica. We need more storage space, so we're upgrading the servers and we're also trying to store the games more efficiently. This post explains some technical details of the new storage format.
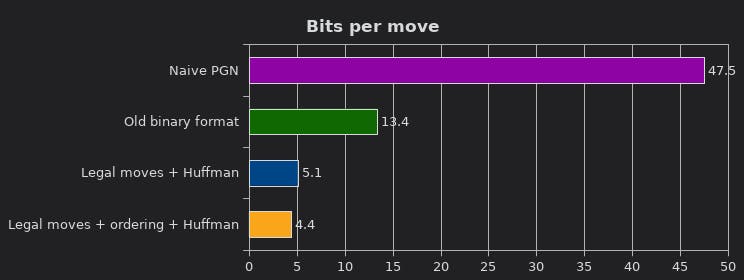
Spoiler alert: The new encoding saves some space.
MongoDB supports transparent Snappy and zlib compression, but it's clear that we can use chess knowledge to perform better than general purpose compression schemes. There are many known approaches. It's all about striking a balance between simplicity of implementation, performance, and compression ratio.
The encoder needs to touch thousands of games per second.
Similar to the way we're compressing clock times, compression works in two steps:
- Map moves to integer indexes. The smaller on average the better.
- Encode those integers as a stream of bits.
Legal move generation
We're trying to map moves to small integers. The first bit of chess knowledge we're going to use is move legality. The maximum number of moves in a chess position seems to be 218, but definitely less than 256. That already narrows it down a lot. (We could stop here, if we were satisfied with 1 byte per move).
To generate legal moves, most chess engines use bitboards (unsigned 64-bit integers) as a way to represent sets of squares. Java has no unsigned integers, but surprisingly (to me) longs are good enough for bitboards: Java has a zero-filling shift operator (>>>), bitwise operations do not treat the sign-bit in a special way, and integer multiplication (used for magic bitboards) also does not care about signedness. Long.numberOfTrailingZeros() can be used for fast bitscans. This means we can easily port Stockfish's legal move generation.
Ordering moves
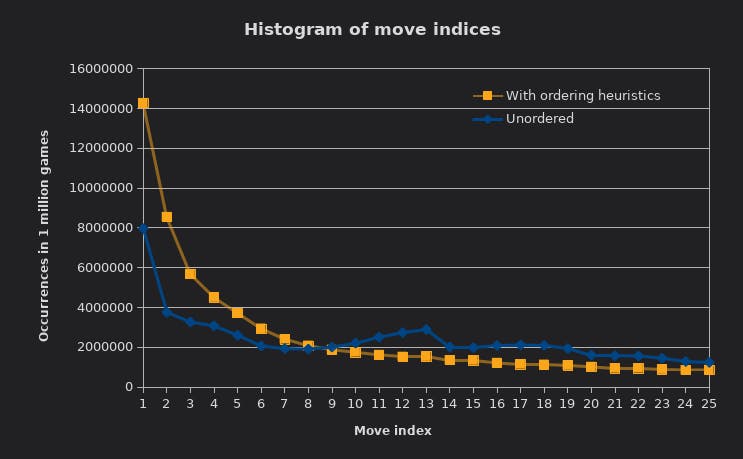
The more left-skewed the histogram, the better the compression.
Not all of the legal moves in a position are equally likely to be played. Most games on Lichess are actually decent chess and far from random. By ordering the candidate moves sensibly we can ensure that smaller indexes are picked on average.
Fully evaluating each move is way too expensive (and also a bit fragile), so we experimented with some very basic criteria. Along the way I ended up implementing the compression scheme in three different languages:
- Python, using python-chess, because it allowed for quick prototyping. Experiments on big PGNs had to run over night.
- Then Rust with shakmaty, rust-pgn-reader and rust-huffman-compress, which are much faster than the Python equivalents and allowed fine-tuning in minutes rather than days.
- And finally Java, so it can run in the JVM like the rest of Lichess. The legal move list can be reused for reading and writing standard algebraic notation, so that reading a 40 move game takes around 100 microseconds.
Weights for various criteria were tuned with SPSA. For now we settled on these, in a strict order of precedence:
- If available, pawn promotions are more likely to be played than other moves.
- Prefer captures.
- Valuable pieces are rarely moved onto squares defended by pawns.
- Usually moves make sense positionally, e.g. centralizing pieces. We use a piece-square table ripped out of a chess engine.
- The order should never allow ties, or else it would leak implementation details. Break ties lexicographically.
Huffman coding
Now that we mapped the moves to a list of integer indexes we can encode them as a stream of bits, reusing Isaacly's fast bit writer from the clock time compression.
Huffman coding is easy to implement, and (almost) optimal when looking at the symbols independently. It works by representing the integer indexes as a set of loose leaves, with weights according to their frequency. Then repeatedly the two lightest nodes are grouped together.
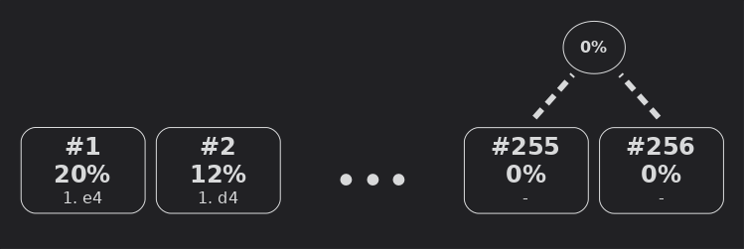
Building a Huffman tree. The weightless nodes were actually given an ϵ weight to break ties.
The result is a binary tree that can be used to read off a unique binary encoding for each index, where more heavy nodes get shorter bitstrings.
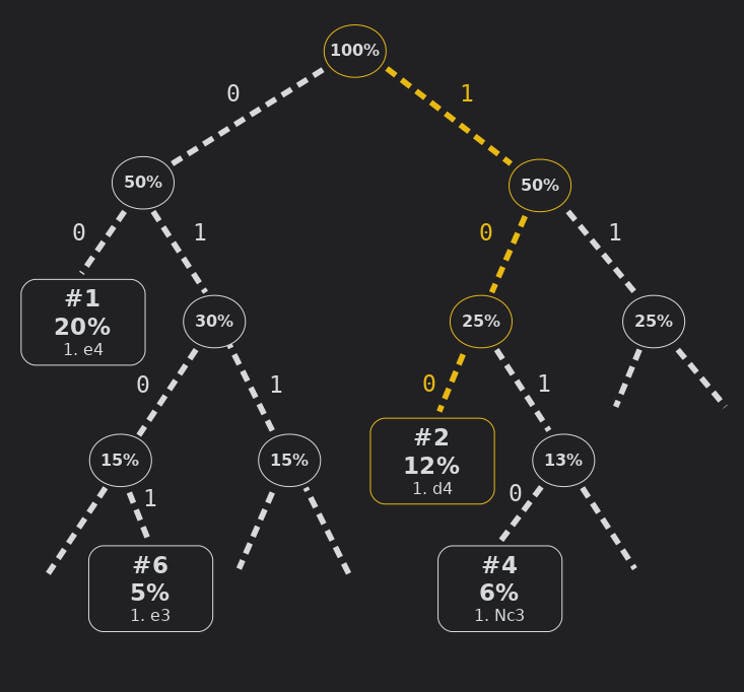
The Huffman tree: For example in the starting position 1. d4 is encoded as 100 (right, left, left).
What's next
The code is published on GitHub. This was a fun project, even though it didn't involve any shiny new features. Your live games are already being encoded with the new format and Thibault wrote a script that is currently migrating existing games. The lichess database contains 680 million games (as of 2018/03/12) so we expect to gain about 70 GB right now and significantly slow the growth of the database from now on.
As always, comments, questions and suggestions are welcome.